Today is the true beginning of my foray into writing performant GPU code. I recently signed up for a MoE kernel writing competition, and the final submission for that is due late April or early May, so basically its game time. I’m starting out with something I have been told will be fundamentally helpful for all of this - working towards writing a cuBLAS-level gemm.
Yesterday, I put some work in (quite a bit of vibe coding tbh) to set up my benchmarking stuff. This took a while, as I am running everything through Modal, meaning I can’t just compile and run and be done with it. I have to compile and then detect and bind to my kernel in python so that I can then launch the code to run this remotely, and send the data back so that I can make graphs of everything. Honestly I’m chill with vibe coding this part for right now, as it is not the most interesting part to me. I think the ideal case is that I go back and do a lot of this by hand, but for this case it feels like boilerplate, so I rest my case.
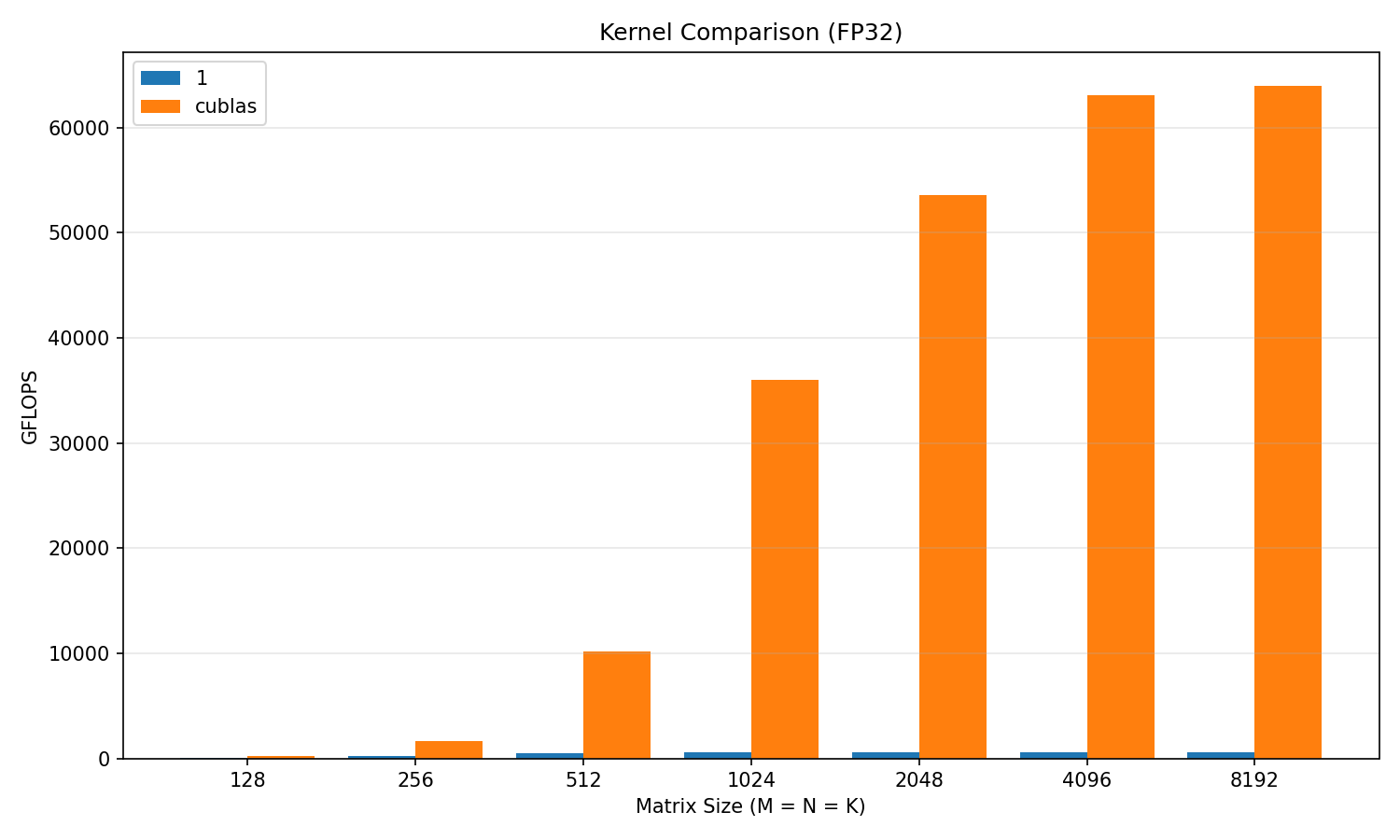
I also wrote the simplest, most naive of unoptimized kernelsHighkey just took it from [this blog](https://siboehm.com/articles/22/CUDA-MMM), highly recommend this resource, and wow. Just wow. It is REALLY bad. I’ll drop a plot below , but at worst it was around 1% of cuBLAS performance. It is most certainly an exciting prospect to see this percentage go up. I’ll do a slightly more advanced approach with Warp-Tiling next, and we shall see how much better it will get with just that.
It has been some time since my last writing. Warp tiling is hard. Very tricky to understand, many moving parts, but I think I have some idea of what is going on now. Rather than write something from scratch for this, I went through a kernel I found in a blog and annotated the crap out of it while rewriting the code. It is pretty unintuitive for me, so I think this was a solid approach. And, as far as I understand, tiling is foundational, but the warp tiling as this stands is quite different from what is to come next. As soon as I can connect to secure wifi, ssh into my machine and run this I will update with new perf!
I have run the new algo! Plots provided below. Turns out my wifi was no issue, but instead OCI deleted my VPS without telling me… Now hosting more securely with Hetzner. Anyways we see big jumps compared to the naive kernel! We are up to 60-70% of cuBLAS on larger matrix sizes, but still below 50% for anything smaller than 1024 x 1024. At the higher sizes, we are peaking around 42 TFLOP/s. The next step of this will be to use the innovations of the Hopper architecture: TMA (Tensor Memory Accelerator), Tensor Cores, and bf16. Until this we have been doing f32, but many of the recent architecture innovations seem geared towards lower precision computation, so I will follow this trend as well.
Once again, to reiterate, I closely followed the implementation of warp-tiling from this blog, as I think it will be more valuable to get to SOTA strategies ASAP. And, to be honest, the indexing is A LOT. Global level, tile level, warp level, warp subtile level, thread level, and even iterating inside the thread level to fill the register accumulator. It takes time to get used to, but it is rewarding to have a deeper understanding of the subject.
For anyone interested, I have more thoroughly annotated my implementation here in the bench folder. I will go back and reread it tonight to see if there is anything confusing / could be explained better. These are exciting times and there are such cool things to learn, until next time!
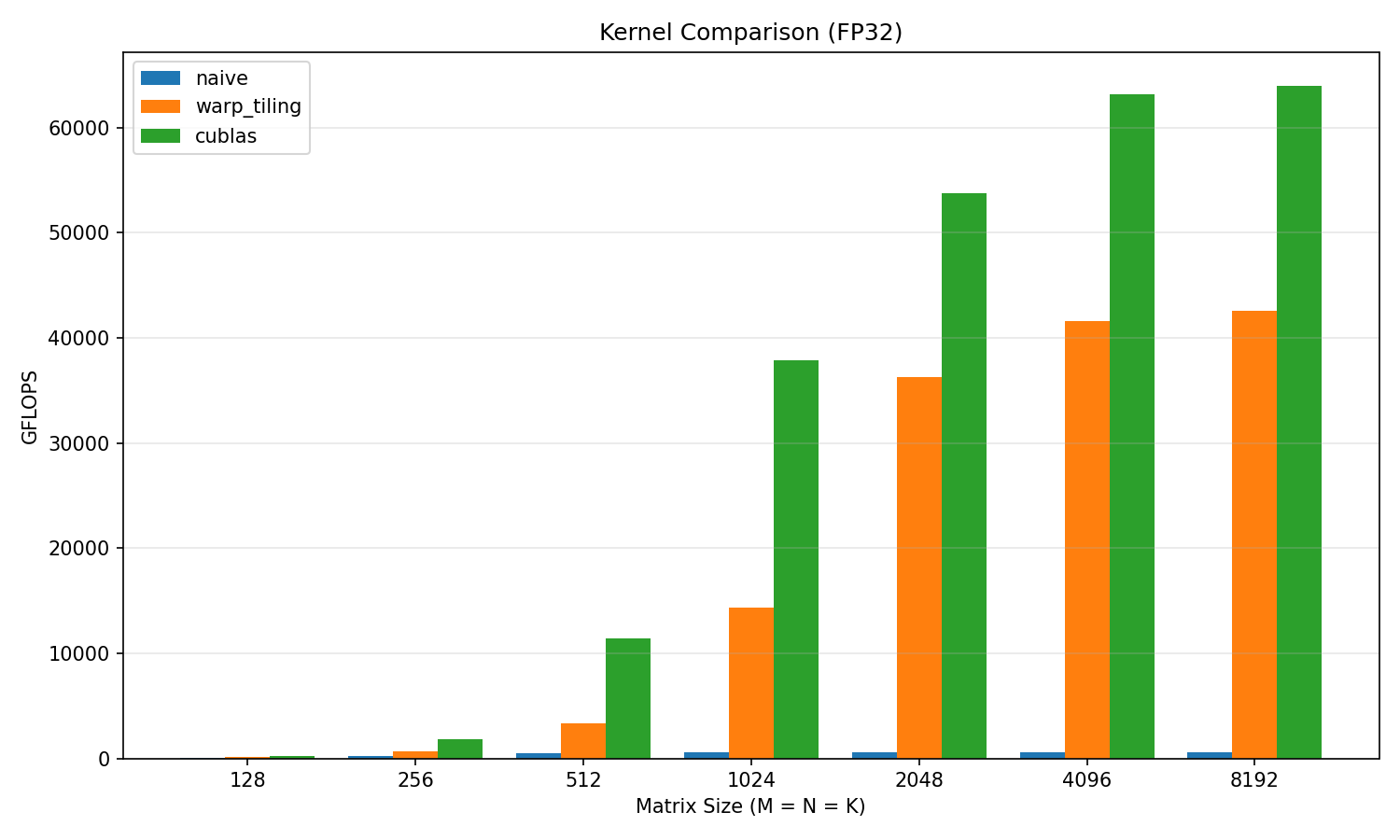
Seems like my previous % of cuBLAS was a lie… Or something like that. I was getting around 40 TFLOPs, but looking into this further the cublas upper bound should be over 1000 TFLOPs… And in FP4 on sparse matrices up to 18000 TFLOPs!
Anyways, I’ve read a fair bit into the next improvements on speed that came with Hopper and Blackwell, and frankly I do not want to write any more of a complex mess than what these involve…
At least not in raw CUDA! Next implementation will be in ThunderKittens, and I’ll talk about the big improvements and come with more plots :)